
We are very happy to announce that Hamid Ghasemirahni successfully defended his PhD thesis (second and final one in the ERC ULTRA project) on November 18, 2024! Marco Chiesa has done a superb job as a co-advisor, and we are very grateful to Prof. Gerald Q. Maguire Jr. for his stellar insights (as usual). Gábor Rétvári was the opponent at the defense, while Paris Carbone served as the Chair. Hamid’s thesis is available online:
In short, this thesis contains the work on Reframer showing a surprising result that deliberately delaying packets can improve the performance of backend servers by up to about a factor of 2 (e.g., those used for Network Function Virtualization). It also includes FAJITA, which shows that a commodity server running a chain of stateful network functions can process more than 170 M packets per second (equivalent of 1.4 Tbps if payloads are stored in a disaggregated fashion as in our earlier Ribosome work [NSDI ’23]!).
A few images from the defense and the celebration are below.
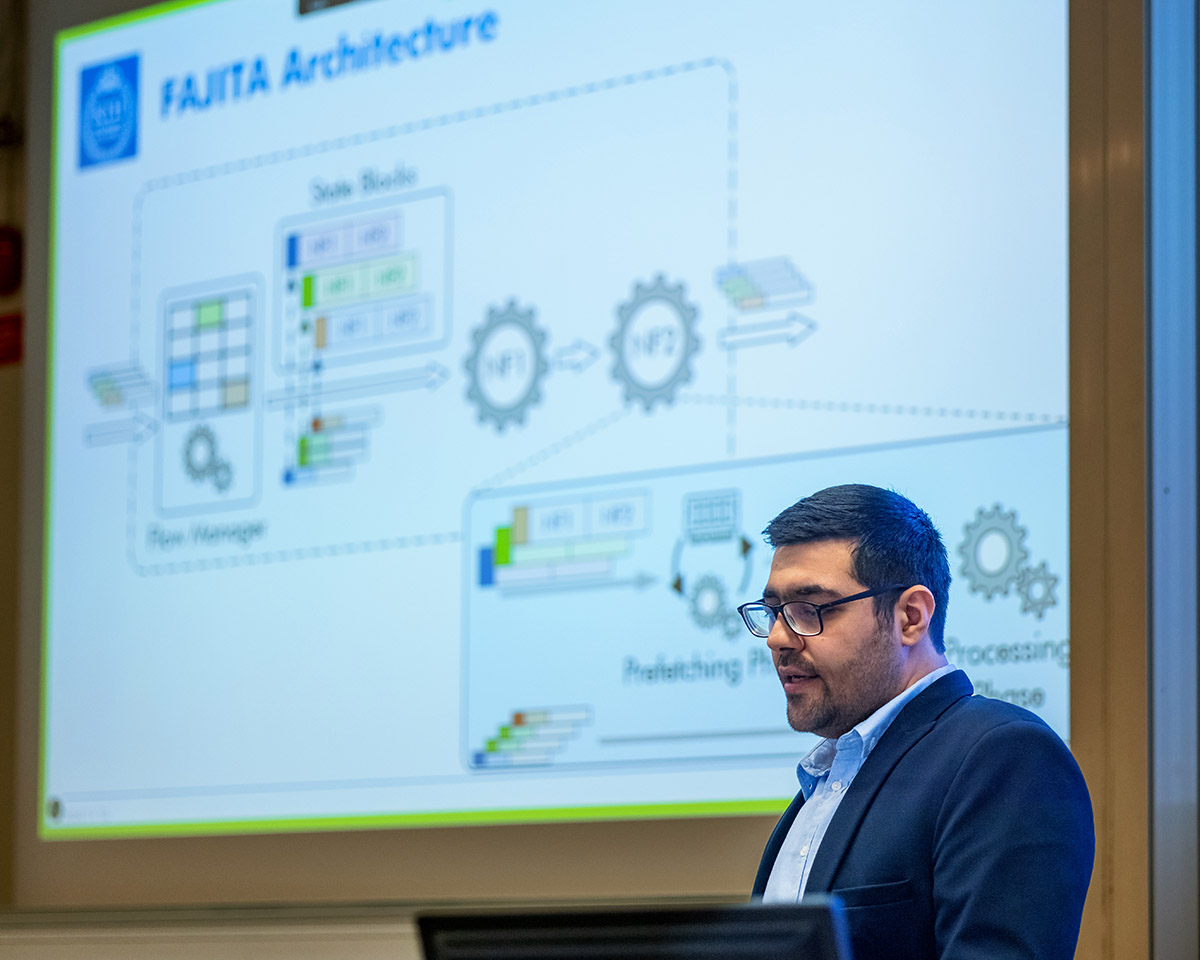
Hamid presenting during the defense (image taken by Dejan Kostic).

Paris congratulates Hamid on the successfully defended PhD thesis (image taken by Dejan Kostic).

Dejan hands the traditional gift to Hamid (image taken by Voravit Tanyingyong).

Group image with colleagues and Dejan (image taken by Voravit Tanyingyong).

Group image (image taken by Voravit Tanyingyong).






