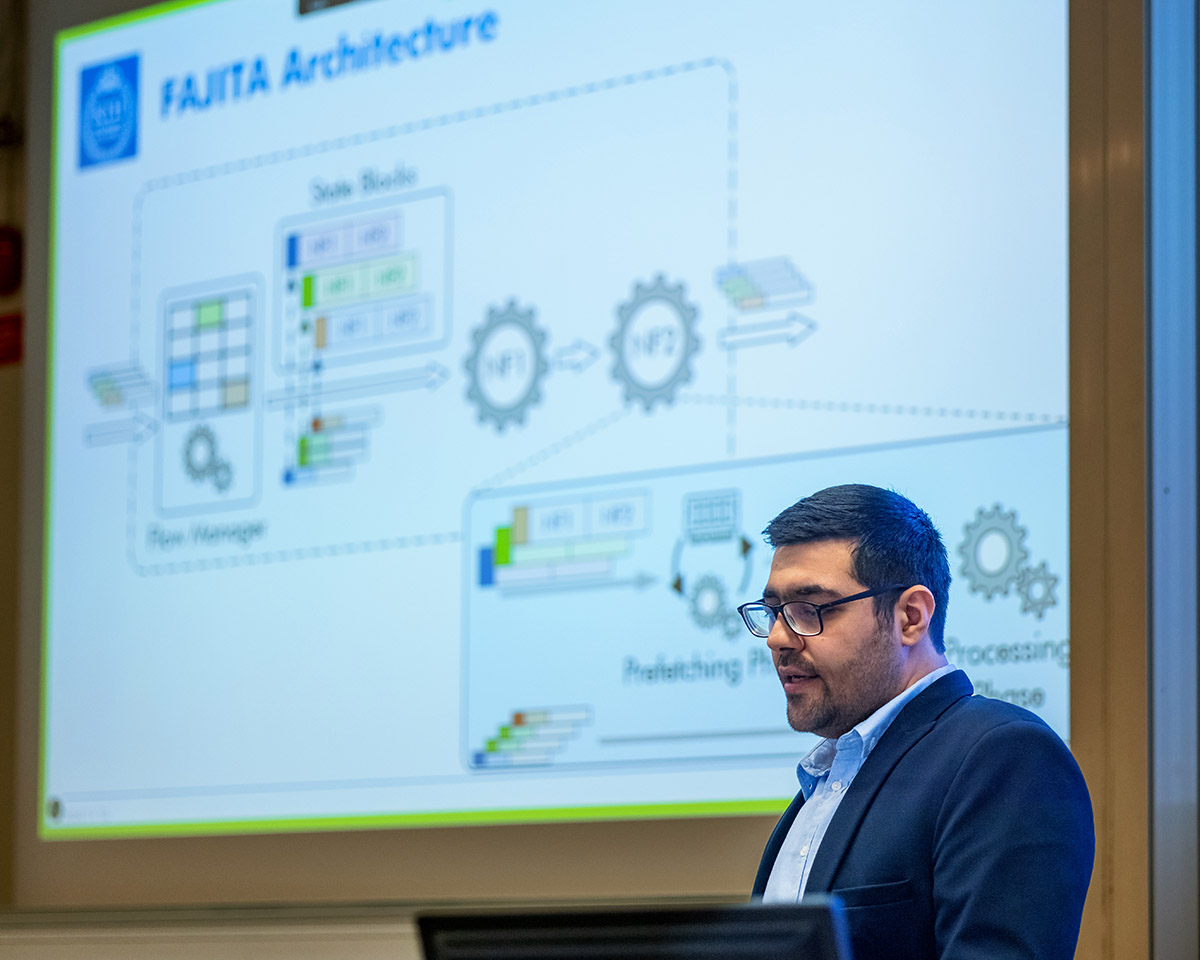
At CoNEXT ’24, Mariano presented our FAJITA paper. This work shows that a commodity server running a chain of stateful network functions can process more than 170 M packets per second (equivalent of 1.4 Tbps if payloads are stored in a disaggregated fashion as in our earlier Ribosome work [NSDI ’23])! Something else that is interesting and perhaps unexpected is that, unless the number of so-called “elephant flows” is very small, spreading incoming packets among the cores using plain Receive Side Scaling (RSS) outperforms existing approaches that perform fine-grained flow accounting and load-balancing. This happens because possible gains get dwarfed by slowdowns in accessing memory.
This is joint work with Hamid Ghasemirahni, Alireza Farshin (now at Nvidia), Mariano Scazzariello (now at RISE), Gerald Q. Maguire Jr., Dejan Kostić, and Marco Chiesa.
Our recording of Mariano’s talk is below:
Data centers increasingly utilize commodity servers to deploy low-latency Network Functions (NFs). However, the emergence of multi-hundred-gigabit-per-second network interface cards (NICs) has drastically increased the performance expected from commodity servers. Additionally, recently introduced systems that store packet payloads in temporary off-CPU locations (e.g., programmable switches, NICs, and RDMA servers) further increase the load on NF servers, making packet processing even more challenging.
This paper demonstrates existing bottlenecks and challenges of state-of-the-art stateful packet processing frameworks and proposes a system, called FAJITA, to tackle these challenges & accelerate stateful packet processing on commodity hardware. FAJITA proposes an optimized processing pipeline for stateful network functions to minimize memory accesses and overcome the overheads of accessing shared data structures while ensuring efficient batch processing at every stage of the pipeline. Furthermore, FAJITA provides a performant architecture to deploy high-performance network functions service chains containing stateful elements with different state granularities. FAJITA improves the throughput and latency of high-speed stateful network functions by ~2.43x compared to the most performant state-of-the-art solutions, enabling commodity hardware to process up to ~178 Million 64-B packets per second (pps) using 16 cores.