

Labb3
Huffmankodning
Börja med att skapa en modell för programmet, som skall redovisas som en egen del vid redovisning. Ett ostrukturerat gränssnitt leder oftast till att labbarbetet försvåras både vid implementation och felsökning.
-
Problem
Problemet består i att implementera ett program som komprimerar filer med hjälp av Huffmankodning. Som en del i detta behöver man göra klasser för att kunna hantera filer på bitnivå. -
Utförande
En beskrivning av vad Huffmankodning är finns i exempeldelen nedan, samt på wikipedia. Det finns även i Abelson/Sussman: "Structure and Interpretation of Computer Programs".
Testning
Du ska testa ditt program. Enklast gör du det genom att generera tester i din IDE (netbeans eller eclipse). Nedan finns ett kommandoradsexempel oberoende av IDE.
Kör programmen Bitfillaesare.java och TestBitfilLaesare.java. Det senare programmet är ett enhetstestprogram (Google junit). Det skapar en fil med ett testbart innehåll och testar att Bitfillaesare.java gör rätt. Prova skapa ett eget testfall. Skapa även ett som fallerar (ändra t.ex. true till false) någonstans. När du är klar med labben ska du skapa egna testfall för din labb.
För att kunna köra program som importerar från junit utan en IDE som netbeans måste miljövariabeln CLASSPATH innehålle sökvägen till junit. Du kan se dina miljövariabler genom att i terminalfönster skriva env på unix/linux/mac eller set i windows terminalfönster (cmd).
Bithantering
Bithanteringen har inte nödvändigtvis något med Huffmankodning att göra. Därför bör denna del av programmet vara generell nog att kunna användas av andra program.
Implementera klasserna BitFileReader och BitFileWriter, som kan läsa respektive skriva enskilda bitar (ettor och nollor) till och från en fil. För att spara data så utrymmessnålt som möjligt måste varje bit som skrivs till fil med BitFileWriter representeras av en enda bit i filen, och inte av ett helt tecken (char) som består av 16 bitar. Den minsta dataenhet som går att skriva till en fil är en byte (byte i Java). BitFileWriter måste därför samla på sig ett flertal bitar innan den kan skriva något till en verklig fil, och BitFileReader måste läsa in flera bitar, för att sedan ge ifrån sig en i taget.
Vid komprimering av en fil skall programmet skapa två filer; en fil som innehåller den komprimerade versionen av källfilen, och en som innehåller en beskrivning av det använda Huffmanträdet (trädet måste sparas så att det går att packa upp den komprimerade filen igen). Det är också möjligt att spara båda dessa filer tillsammans som endast en fil, men det är varken nödvändigt eller rekommenderat i detta fall. Eftersom man förmodligen vill kunna komprimera flera olika filer så bör namnen på samtliga filer som komprimeringsprogrammet skapar (trädfil, komprimerad fil) skilja sig från originalfilen, t.ex. genom att användaren får ange samtliga filnamn eller alternativt kan programmet lägga på ändelser på orginalfilnamnet.
Vid dekomprimering skall programmet med hjälp av den komprimerade filen och det sparade Huffmanträdet skapa en fil som är innehållsmässigt identisk med källfilen.
Programmet skall uppfylla följande:- Klasserna BitFileReader och BitFileWriter skall ha ett klart definierat gränssnitt. Inga metoder utanför gränssnittet får användas i resten av koden.
- Det ska finnas junit tester som testar ovanstående gränssnitt.
- BitFile-klasserna skall inte utföra någon del av Huffmankodningen. De opererar alltid på samma sätt, oavsett hur indata ser ut.
- Programmet skall klara av att komprimera godtyckliga filer, det vill säga inte bara textfiler eller annan speciell typ av filer.
- Programmet skall klara av att komprimera filer av rimlig storlek, i princip hundratals GB (även om vi knappast testar det).
- Alla mellansteg (producerade filer) skall finnas kvar, så att de kan jämföras.
-
Tips och exempel
I kurskatalogen(/afs/nada.kth.se/misc/info/DA3001/suoop09/bin/) finns ett program som heter binary som kan användas vid felsökning, programmet kan köras endast på maskinen my.nada.kth.se, du behöver alltså logga in på my.nada.kth.se med kommandot ssh my.nada.kth.se för att kunna köra det. Programmet skriver ut enskilda bitar från en fil så att man på ett enkelt sätt kan se exakt vad filen innehåller. Nedan följer ett exempel på hur programmet fungerar.
pem@my> echo ABCDE > test.bin
pem@my> binary test.bin
01000001 01000010 01000011 01000100 01000101 [ABCDE]
00001010 [. ]
pem@my>
Den första raden skapar en fil som heter test.bin som innehåller tecknen ABCDE. I kolumnen längst till höger återfinns innehållet i filen utskrivet med vanliga tecken. För ytterligare detaljer om binary, kör binary -help. Alternativ kan du använda en sida på nätet t.ex ascii-text-to-binary-converter.
Nedan följer ett exempel på hur huffmanprogrammet skulle kunna fungera:
~pem> java encode
Usage: java encode
~pem> java encode source tree enCoded
~pem> ls -l source tree enCoded
total 24
-rw-r--r-- 1 pem 30 3471 Dec 5 14:55 enCoded
-rw-r--r-- 1 pem 30 6425 Dec 5 14:53 source
-rw-r--r-- 1 pem 30 225 Dec 5 14:55 tree
~pem> java decode
Usage: java decode
~pem> java decode enCoded tree deCoded
~pem> ls -l source tree enCoded deCoded
total 38
-rw-r--r-- 1 pem 30 6425 Dec 5 14:56 deCoded
-rw-r--r-- 1 pem 30 3471 Dec 5 14:55 enCoded
-rw-r--r-- 1 pem 30 6425 Dec 5 14:53 source
-rw-r--r-- 1 pem 30 225 Dec 5 14:55 tree
~pem> diff source deCoded
~pem>Genom att köra ls -l kan man se hur stora respektive filer är. Programmet diff kan användas för att jämföra om två filer är innehållsmässigt lika. Om filerna är olika skriver diff ut ett meddelande som beskriver skillnaden mellan filerna. Om filerna är lika avslutas diff utan utskrifter. I kurskatalogen finns ett par olika exempelfiler, inputNNN.bin. Programmet skall klara av att komprimera samtliga filer.
-
Beskrivning av Huffmankodning
Det vanligaste sättet att representera tecken är att ge alla tecken en kod med samma längd. På Nadas unixdatorer används t.ex. åtta bitars ascii. Där representeras alla tecken av åtta bitar. 'A' motsvaras t.ex. av (01000001). Huffmankodning bygger på att ge vanligt förekommande tecken kortare koder än mindre vanliga tecken, och på så sätt få en totalt sett kortare kodning av ett meddelande.
Om t.ex. meddelandet (ACCAAACCBBBDADED) skulle representeras i åtta bitars ascii skulle meddelandet vara 16 bytes, vilket blir 16 * 8 = 128 bitar. För att Huffmankoda ett meddelande är det första steget att skapa en frekvenstabell över de olika tecknen i meddelandet. För meddelandet ovan blir det
tecken frekvens A 5 C 4 B 3 D 3 E 1 För att bygga kodträdet skapar man fem noder utgående från frekvenstabellen. Varje nod innehåller en frekvens och ett tecken. Kodträdet byggs nu genom att hela tiden välja de två noder som har lägst frekvens, och skapa en ny nod av dem. Den skapade noden ersätter de båda utvalda noderna, och får som frekvens summan av de båda utvalda nodernas frekvenser. För att lättast kunna välja de två med lägst frekvens kan man hålla noderna sorterade med avseende på frekvens. I fallet ovan får man
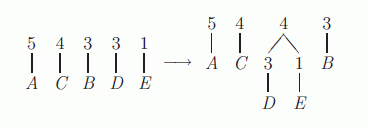
Genom att fortsätta på detta sätt så länge det finns mer än en nod kvar får man följande
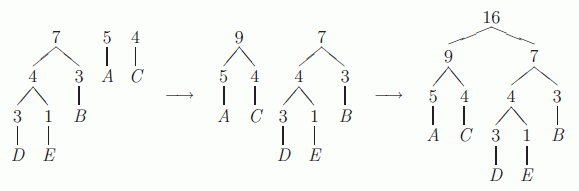
Det sista är alltså det slutgiltiga trädet. För att sedan få fram koden för ett specifikt tecken börjar man vid roten av trädet, sedan går man ner genom trädet till det tecken man vill ha koden för. På vägen ner genom trädet lägger man till en etta på koden om man går åt höger och en nolla om man går åt vänster.
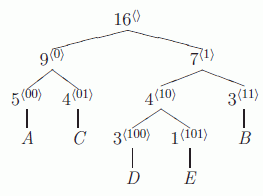
För de tecken det rör sig om får man alltså följande tabell: tecken kod längd
A 00 2 C 01 2 B 11 2 D 100 3 E 101 3 För att koda ett meddelande byts varje tecken i meddelandet ut mot respektive kod. I fallet ovan blir det kodade meddelandet:
000101000000010111111110000100101100
Om meddelandet Huffmankodas istället för att lagras som åtta bitars ascii, får man alltså en totallängd på 36 bitar, istället för 128 bitar. Som synes fick tecknen med de lägsta frekvenserna de längsta koderna. En annan egenskap hos de konstruerade koderna, är att ingen kod inleds med någon annan kod. Denna sista egenskap är av betydelse när man vill ha tillbaka meddelandet i klartext med hjälp av det kodade meddelandet (annars hade det inte gått att avgöra var en kod slutade och nästa började).
För att få tillbaka det kodade meddelandet använder man sig enklast av kodträdet. Man läser det kodade meddelandet bit för bit. Om den lästa biten är en etta går man åt höger, och annars åt vänster. När man till slut kommer ned till ett löv i trädet, har man ett tecken i originalmeddelandet, och man kan börja om från roten av trädet med nästa kod.