
PhD Material
Data
Chinese Whispers: A Multimodal Dataset for Embodied Language Grounding
We introduce a multimodal dataset in which subjects are instructing each other how to assemble IKEA furniture. Using the concept of "Chinese Whispers", an old kids' game, we employ a novel method to avoid implicit experimenter biases. We let subjects instruct each other on the nature of the task: the process of the furniture assembly. Uncertainty, hesitations, repairs and self-corrections are naturally introduced in the incremental process of establishing common ground. The corpus consists of 34 interactions, where each subject first assembles and then instructs. We collected speech, eye-gaze, pointing gestures, and object movements, as well as subjective interpretations of mutual understanding, collaboration and task recall. The corpus is of particular interest to researchers who are interested in multimodal signals in situated dialogue, especially in referential communication and the process of language grounding.

Corpus. The corpus consists of a total of 34 interactions. All recordings (mean length of assembly task: 3.8 minutes) contain data from various sensors capturing motion, eye gaze, gestures, and audio streams.
*For data privacy reasons, video and audio data are not publicely available (only gaze and speech automatic annotations).
License. The data are licensed under Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0). This license allows you to use the data free of charge for non-commercial purposes. You may modify the data as long as you keep the attribution to the original in all the files, publish your work under the same licencse and cite Kontogiorgos et. al 2020.
Data. Data combined from different sensors (motion capture, eye tracking glasses, microphones) contain actions and object movements, speech, eye gaze and head orientation information, pointing gestures.
In order to get access to the corpus, send an email with a request to Dimosthenis Kontogiorgos at or Joakim Gustafson at . Users will be required to sign an EULA form before getting access to the dataset. A sample of the dataset is available at DOI: 10.5281/zenodo.4587308 and URL: zenodo.org/record/4587308#.YEOnWF1KhEI.
Citation
For a detailed description of the corpus refer to our paper:
@inproceedings{kontogiorgos2020lrec,
author = {Dimosthenis Kontogiorgos, Elena Sibirtseva, and Joakim Gustafson},
title = {{Chinese Whispers: A Multimodal Dataset for Embodied Language Grounding}},
year = {2020},
booktitle = {Language Resources and Evaluation Conference LREC 2020},
}
A Multimodal Corpus for Mutual Gaze and Joint Attention in Multiparty Situated Interaction
In this corpus of multiparty situated interaction participants collaborated on moving virtual objects on a large touch screen. A moderator facilitated the discussion and directed the interaction. The corpus contains recordings of a variety of multimodal data, in that we captured speech, eye gaze and gesture data using a multisensory setup (wearable eye trackers, motion capture and audio/video). In the multimodal corpus, we investigate four different types of social gaze: referential gaze, joint attention, mutual gaze and gaze aversion by both perspectives of a speaker and a listener. We annotated the groups’ object references during object manipulation tasks and analysed the group’s proportional referential eye-gaze with regards to the referent object. When investigating the distributions of gaze during and before referring expressions we could corroborate the differences in time between speakers’ and listeners’ eye gaze found in earlier studies. This corpus is of particular interest to researchers who are interested in social eye-gaze patterns in turn-taking and referring language in situated multi-party interaction.

Corpus. The corpus consists of a total of 15 hours of recordings of triadic task-oriented interactions. All recordings (roughly one hour each) contain data from various sensors capturing motion, eye gaze, audio and video streams. Out of the 15 sessions, 2 sessions have no successful eye gaze calibration and are discarded. One session has synchronisation issues on the screen application which is also discarded. One session has large gaze data gaps and is discarded as well. The rest 11 sessions of the aggregated and processed data from the corpus are further described on the paper published at LREC 2018 that can be found here.
*For privacy reasons, only the annotations are public.
Annotations. We have annotated referring expressions to objects on the display by looking at what object the speaker intended to refer to. For the annotations we used the videos of the interactions together with the ASR transcriptions and the current state of the app (visible objects or current screen on the large display). As linguistic indicators we used full or elliptic noun-phrases, pronouns, possessive pronouns and spatial indexicals. The ID of the salient object or location of reference was identified and saved on the annotations. As of June 2018, we have annotated 766 referring expressions out of 5 sessions, roughly 5 hours of recordings which is about one/third of our corpus.
License. The data are licensed under Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0). This license allows you to use the data free of charge for non-commercial purposes. You may modify the data as long as you keep the attribution to the original in all the files, publish your work under the same licencse and cite Kontogiorgos et. al 2018.
Data. The dataset is a collection of interactions where a human moderator helps two human participants to arrange furniture in a virual flat. The dataset consists of timestamped data points split by 100ms that have the following information [Frame, Time, M Gaze, P1 Gaze, P2 Gaze, M Room, P1 Room, P2 Room, M ASR, P1 ASR, P2 ASR, Annotation Room M, Annotation Room P1, Annotation Room P2, Annotation Object M, Annotation Object P1, Annotation Object P2]. The Gaze cells refer to a collection of potential gaze targets per participant, while the Room cells refer to what room in the virual flat each participant is gazing at. The annotation room cells include the annotated references from the speaker to the referred room and likewise for the object cells. For each frame a collection of objects as gaze targets is given with the distance (in pixels) from the gaze vector to the object: 33@103|34@87|42@98|43@70|. Here, the first object with ID 33 is 103 pixels away from the participant's gaze vector.
In order to get access to the corpus, send an email with a request to Dimosthenis Kontogiorgos at or Joakim Gustafson at . Users will be required to sign an EULA form before getting access to the dataset.
Citation
For a detailed description of the corpus refer to our paper:
@inproceedings{kontogiorgos2018lrec,
author = {Dimosthenis Kontogiorgos, Vanya Avramova, Simon Alexandersson, Patrik Jonell, Catharine Oertel, Jonas Beskow, Gabriel Skantze and Joakim Gustafson},
title = {{A Multimodal Corpus for Mutual Gaze and Joint Attention in Multiparty Situated Interaction}},
year = {2018},
booktitle = {Language Resources and Evaluation Conference LREC 2018},
}
Code
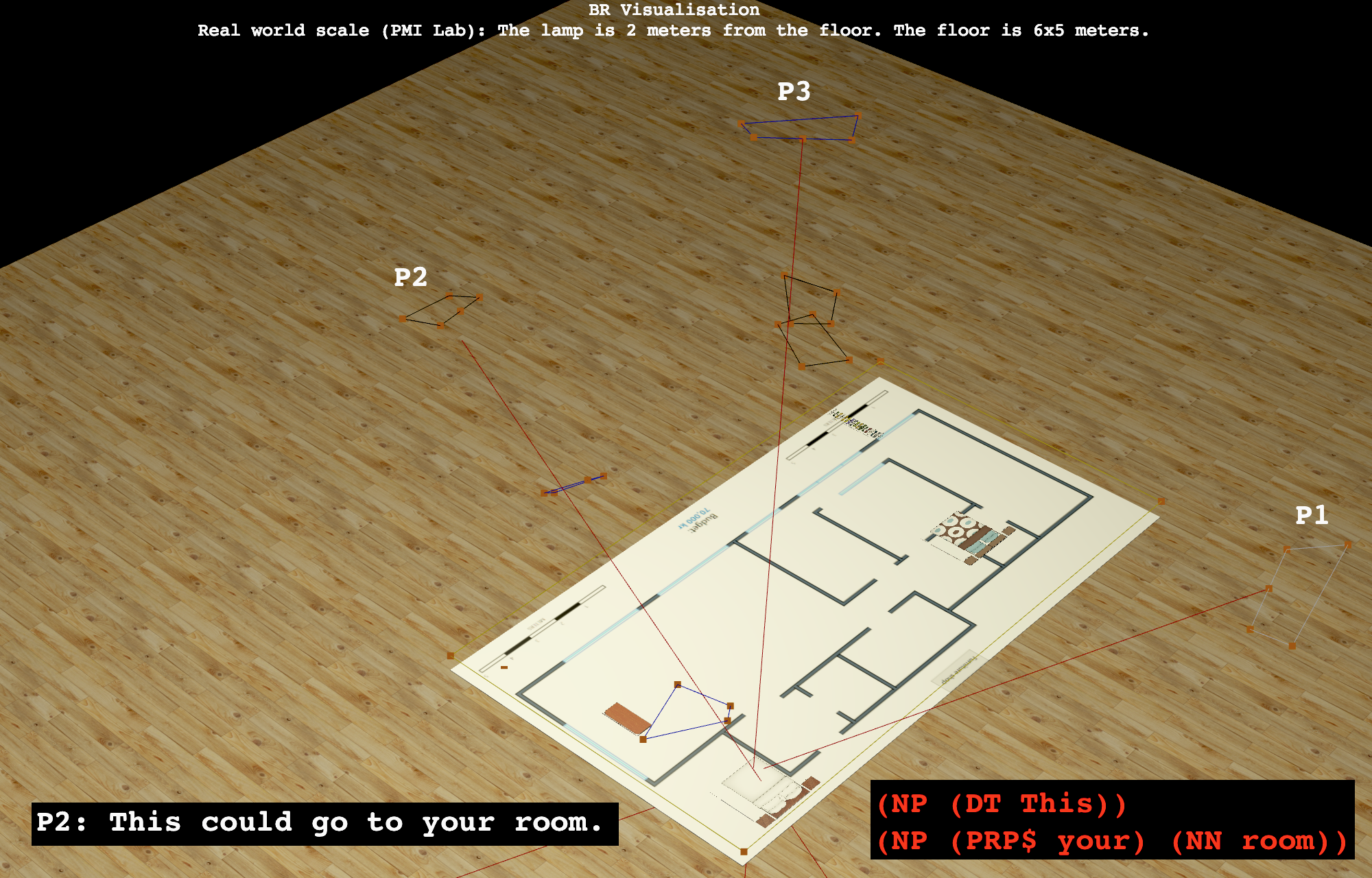
Real-time eye-gaze & mocap visualisation
In this visualisation tool we use WebGL and Three.js to visualise in real time motion capture and eye tracking data, combined with syntactic parsing in natural language.
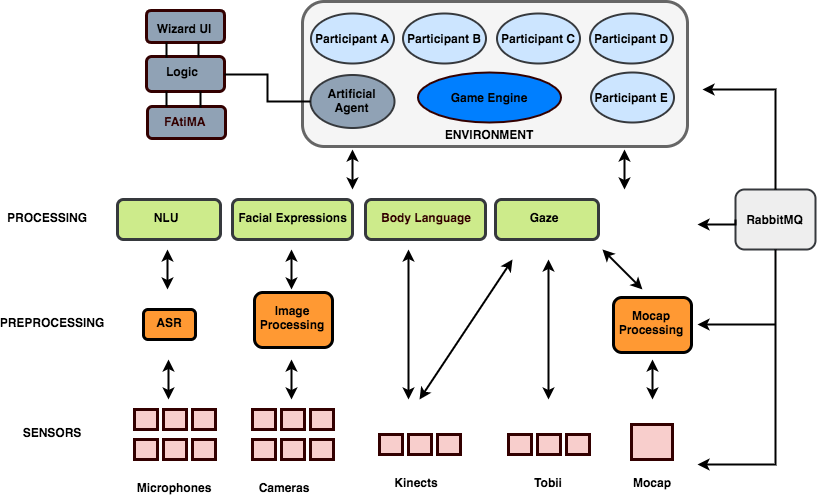
Multisensory processing architecture
We present a processing architecture used to collect multimodal sensor data, both for corpora collection and real-time processing. The code for the implemented architecture is available as an open-source repository under Apache License v2. The architecture is agnostic to the choice of hardware (e.g. microphones, cameras, etc.) and programming languages, although our framework implementation is mostly written in Python. The architecture is of particular interest for researchers who are interested in the collection of multi-party, richly recorded corpora and the design of conversational systems. Moreover for researchers who are interested in human-robot interaction the available modules offer the possibility to easily create both autonomous and wizarded interactions.
Citation
For a detailed description of the architecture and framework refer to our paper:
@inproceedings{jonell2018lrec,
author = {Patrik Jonell, Mattias Bystedt, Per Fallgren, Dimosthenis Kontogiorgos, José Lopes, Zofia Malisz, Samuel Mascarenhas, Catharine Oertel, Eran Raveh and Todd Shore},
title = {{ARMI: An Architecture for Recording Multimodal Interactions}},
year = {2018},
booktitle = {Language Resources and Evaluation Conference LREC 2018},
}
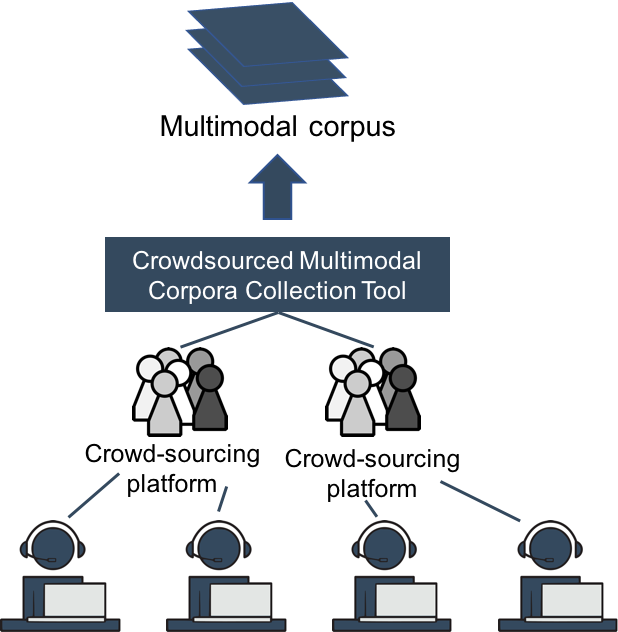
Multimodal corpora crowdsourcing collection
We are proposing a novel tool which will enable researchers to rapidly gather large amounts of multimodal data spanning a wide demographic range. The code is released under an Apache License 2.0 and available as an open-source repository which will allow researchers to set-up their own multimodal data collection system quickly and create their own multimodal corpora.
Citation
For a detailed description of the tool refer to our paper:
@inproceedings{jonell2018lrec,
author = {Patrik Jonell, Catharine Oertel, Dimosthenis Kontogiorgos, Jonas Beskow and Joakim Gustafson},
title = {{Crowdsourced Multimodal Corpora Collection Tool}},
year = {2018},
booktitle = {Language Resources and Evaluation Conference LREC 2018},
}
