
FonaDyn – Phonatory Dynamics
The human vocal apparatus is an amazing machine that is capable of producing and imitating a huge repertoire of sounds. It has many degrees of freedom, with large variations both between speakers and within speakers. It is an interconnected whole in which no individual parameter can change without affecting most others. This variability presents a challenge to our understanding of voice production, and hampers objective measurements: the management of voice problems is still based mostly on subjective perceptual assessments by clinicians. Quantitative norms for voice diagnosis and therapy remain elusive, which is problematic for evidence-based care. In this long-running project, we seek ways of describing and accounting for the many sources of variation in voice sounds.
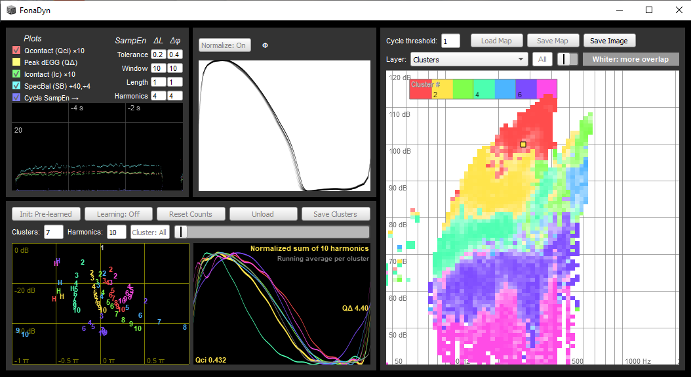
Variation with vocal loudness and pitch can be navigated by sampling voice signal metrics over a dense grid of level and frequency, thus building ‘voice map’ images that can be very informative. Crucially, voice maps of individuals are reproducible, allowing for pre/post-intervention comparisons. Here we investigate the potential of voice mapping to improve the understanding, documentation, and assessment of clinical interventions. While voice ranges are established clinical metrics, the notion of surface mapping of voice signal features is not. We expect features derived from such maps to have much greater clinical and pedagogical relevance than prevalent but undersampling methods. The main goal here is to find such features, at a higher level of representation than before. In international collaboration with clinicians and voice teachers, we seek to relate established perceptual variables to the physical metrics, and test the concept of showing clinicians ‘the big picture’. In effect, we seek a paradigm shift in voice measurement, from a ‘keyhole view’ to a ‘landscape view’ of the voice. An important tool for this inquiry is a realtime interactive analysis application software FonaDyn (pictured), which we are continually developing, and have placed in the public domain.
Staff:
Sten Ternström (Project leader)


Funding:
KTH-CSC scholarship
KTH faculty funds