
AI och informationssökning
AI-verktyg kan göra det snabbare och enklare att söka vetenskaplig information. Samtidigt är det viktigt att vara medveten om risker med felaktiga uppgifter och påhittade referenser. På den här sidan får du lära dig om vad AI-verktyg för sökning är och vad du bör tänka på när du använder dem.
Artificiell intelligens (AI) är ett brett begrepp, och vissa tekniker har varit i bruk länge, till exempel för relevansrankning och rekommendationer om liknande innehåll. Under de senaste åren har användningen av stora språkmodeller och generativ AI blivit allmänt spritt och använt.
Generativ AI
Generativ AI innebär att AI används för att generera digitalt innehåll. Det digitala innehållet kan vara text, bild, musik eller annat material.
Generativ AI bygger till stor del på sannolikhet. Om en text börjar så här, hur borde den fortsätta? Vilka ord och meningar brukar förekomma tillsammans? Utifrån detta genereras en unik text. Eftersom den innehåller vanligt förekommande kombinationer av ord och meningar kommer texten att se sannolik och trovärdig ut. Faktauppgifter kommer ofta att stämma, men kan också vara helt felaktiga. Detta brukar kallas att AI-verktyget hallucinerar.
Vanligtvis bygger generativ AI på stora språkmodeller som kan processa naturligt språk. De är tränade på stora mängder data. Vilka data som använts kommer att ha stort inflytande på hur modellen fungerar. Datat är oftast begränsat i tid och information om nyare händelser och ny forskning kan saknas. Datat kan också vara snedvridet eller “biased” på olika sätt. De flesta språkmodeller anger inte tydligt vilket data som använts som träningsdata, vilket är en nackdel i akademiska sammanhang där transparens är viktigt.
Använda generativ AI för att söka information
Verktyg som helt bygger på generativ AI kan inte ange källor för informationen. AI-verktyget har inte sökt upp information utan bara genererat en text. Om ett renodlat generativ AI-verktyg anger referenser kan det vara påhittade referenser som inte finns i verkligheten. I ett akademiskt arbetssätt är referenser och granskning av källor viktigt. Det är viktigt att veta varifrån information ursprungligen kommer och att kunna gå tillbaka och granska de källor som en text bygger på. Utan angivna källor blir det inte möjligt, och renodlad generativ AI är därför inte lämpligt att använda för vetenskaplig informationssökning.
Många av de chattbotar som initialt var helt baserade på generativ AI gör numera sökningar, oftast på Internet. Det gäller till exempel Bing, Bard och vissa versioner av ChatGPT. Den här utvecklingen innebär att chattbottarna och sökning på Internet med hjälp av en sökmotor har närmat sig varandra. Bådadera kan vara bra sätt för att komma igång och skaffa sig en första överblick över ett ämne. Det är bra att kolla upp vilka källor ett påstående kommer ifrån och bedöma hur pålitlig informationen verkar vara.
AI-drivna verktyg för sökning
En rad AI-baserade verktyg för sökning har utvecklats. Många bygger på Retrieval Augmented Generation (RAG). RAG innebär att sökning i en extern källa kombineras med språkmodellen. Sökningen kan ske på Internet eller i databaser som till exempel kan innehålla vetenskapliga publikationer. Sökningen är i regel någon form av semantisk sökning. Semantiskt innebär att det handlar om likhet i mening eller betydelseinnehåll, till skillnad från likhet mellan tecken, ord och fraser, som traditionell (lexikal) sökning använder sig av.
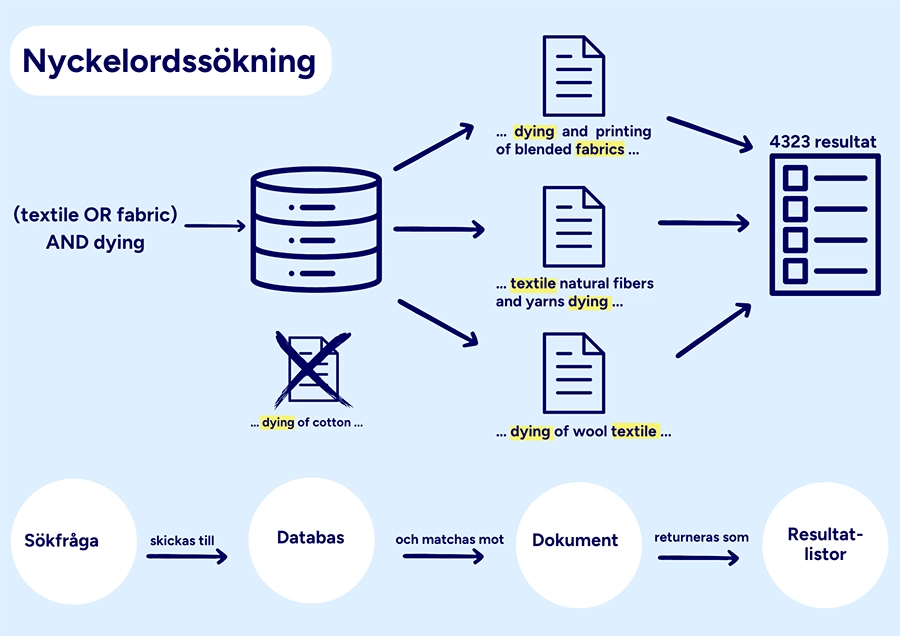
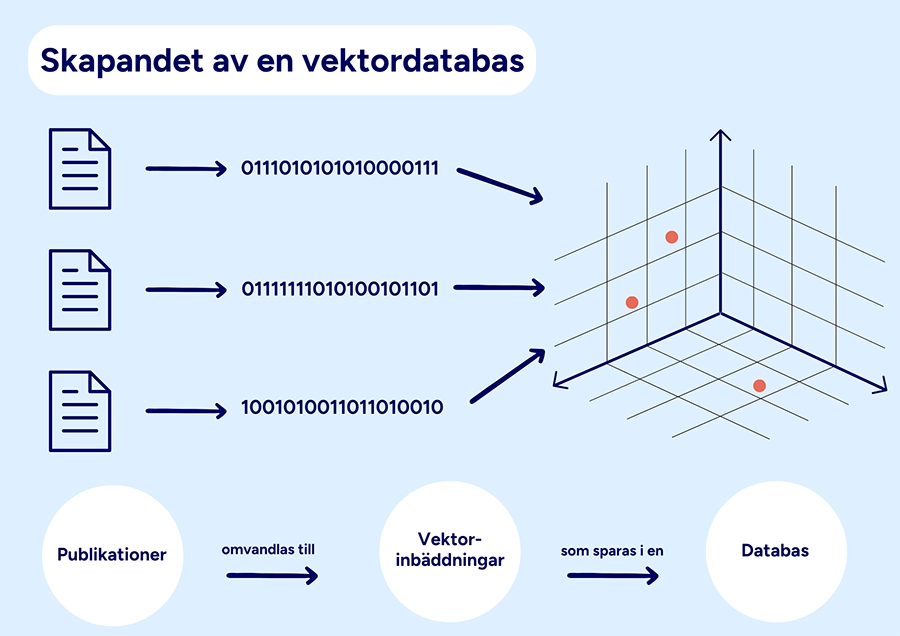
Den semantiska sökningen i RAG bygger i de flesta fall på vektorinbäddningar. Dokumenten i databasen representeras av vektorinbäddningar, serier av siffor.
När du söker omvandlas även din sökfråga eller prompt till en vektorinbäddning. En jämförelse mellan den vektorinbäddning som representerar sökfrågan och vektorinbäddningarna i databasen görs. Som sökresultat presenteras de publikationer som i högst grad liknar sökfrågan eller prompten. Språkmodellen och den semantiska sökningen kombineras ofta med andra metoder för att söka och sortera information, som nyckelordssökning, relevansrankningsalgoritmer och citeringsanalys.
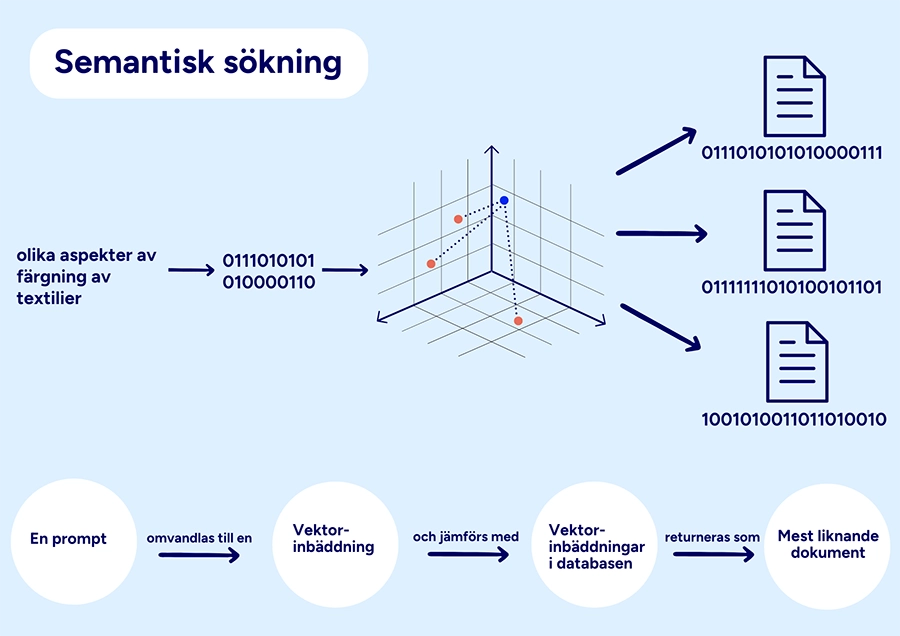
Antalet källor som presenteras i resultatet är i RAG-verktygen ofta ganska litet, och resultatet innehåller lika många källor oavsett vilken prompt som används. Sökning i ett RAG-verktyg innebär att källorna rankas utifrån större eller mindre grad av likhet, inte att återfinna källor som exakt matchar en sökfråga.
I RAG-baserade sökverktyg är risken för fabricerade referenser i stort sett obefintlig. De referenser som presenteras kommer att existera. Däremot kan hallucinationer i genererade texter fortfarande förekomma. Det är inte heller säkert att information som påstås vara hämtad ur en viss källa faktiskt återfinns där.
Det finns ett antal RAG-baserade verktyg som är inriktade på vetenskaplig litteratur. Ofta är det inte redovisat exakt vilka datakällor de använder, men Semantic Scholar och OpenAlex är vanligt förekommande. Verktygen har i regel tillgång till fulltext för vissa vetenskapliga artiklar, men inte till alla. För de artiklar där åtkomsten är begränsad kommer verktygens analys av källorna att baseras på titel och abstrakt. Vad gäller böcker, och i synnerhet tryckta sådana, så ingår de sällan i de använda datakällorna.
Möjligheter
RAG kan vara ett bra komplement till lexikal sökning i traditionella databaser. Det är lättare att formulera en fråga i naturligt språk än att konstruera en bra sökning med nyckelord och booleska operatorer. Den semantiska sökningen kan göra att källor återfinns som annars skulle ha missats. De sammanfattningar som genereras kan vara en hjälp för att snabbare kunna hitta relevanta källor. Tänk dock på att sammanfattningarna inte alltid är rättvisande och läs originalkällorna om du vill använda dem i ditt eget arbete
I de flesta RAG-baserade verktyg kan du formulera din sökfråga eller prompt med naturligt språk. Oftast är det bäst att fokusera på att beskriva ämnet och undvika “prompt engineering” som fungerar i chatbottar. Fraser som handlar om hur svaret ska utformas, vilken typ av källor som ska väljas ut och annat som inte beskriver själva ämnet riskerar att hamna i konflikt med RAG-verktygets egen funktionalitet och kan försämra resultatet.
Risker
En nackdel med de RAG-baserade verktygen är att det inte är transparent hur sökning och urval sker. Det går inte att förstå varför just de presenterade källorna återfinns, och inte heller hur rankningen går till.
Även reproducerbarheten brister. Reproducerbarhet innebär att någon annan ska kunna upprepa till exempel ett vetenskapligt experiment och få samma resultat. Vad gäller sökning så ska samma sökning utförd av olika personer ge samma resultat, liksom samma sökning utförd vid olika tillfällen. Det ligger i den generativa AI:ns natur att varje genererad text ska vara unik. Även vad gäller återfunna källor kommer en och samma sökfråga upprepad vid olika tillfällen eller av olika personer i många fall att ge olika resultat. Detta gör det omöjligt att utföra systematiska sökningar med dessa verktyg.
Nyckelordssökning i en traditionell databas ger ofta en överblick av forskningen om en viss fråga. Antalet träffar ger en indikation på hur mycket ämnet beforskats, och genom att gå igenom träfflistan kan man bilda sig en uppfattning om vilka teman som är vanliga. Vid sökning i ett RAG-baserat verktyg får man i de flesta fall inte denna överblick. Du får samma antal träffar, oavsett hur mycket eller lite forskning det finns inom det område du frågar efter.
Användningsvillkor och upphovsrätt
Många AI-verktyg sparar det du matar in och använder det på olika sätt, bland annat som träningsdata. Läs användningsvillkoren för respektive tjänst för att få veta mer, och var aktsam om du till exempel matar in någon annans material eller känsliga uppgifter.
Upphovsrätt gäller bara material som skapats av fysiska personer. AI-genererade bilder och text omfattas därför inte. Ingen har upphovsrätt till AI-producerat material. Däremot kan det finnas restriktioner för hur materialet får användas. Dessa restriktioner hittar du i användningsvillkoren du accepterade när du skapade ett konto för tjänsten.
Fusk och plagiat
Innan du använder AI-verktyg i dina studier behöver du kolla upp vilka riktlinjer som gäller i den aktuella kursen. Generellt gäller att du aldrig ska lämna in ett arbete som ditt eget om du inte i väsentliga delar genomfört det själv. För transparensens skull kan det vara bra att ange vilka verktyg du använt, och på vilket sätt. KTH:s sidor om fusk och plagiering innehåller mer information.
AI-verktyg som referens
Praxis varierar för om AI-verktyg ska anges som referenser. De är inga källor i traditionell mening och enligt vissa rekommendationer bör de snarare nämnas som använda verktyg. Om du ska ange AI-verktyg som referenser kan du ibland hitta exempel på hur du kan göra det i guiden till den referensstil du använder.
